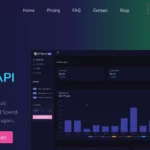
Lilac is an AI tool designed to assist in the curation of data for the purpose of fine-tuning datasets. This tool can be accessed either through its open-source LLMS UI or Python API. With Lilac, users have the ability to explore datasets, annotate and structure data, detect PII and profanity, analyze text statistics, conduct semantic and conceptual searches, cluster data, and eliminate duplicate labeling.
In addition, Lilac offers the option to curate data through bulk labeling and perform semantic keyword searches on large datasets. It is fully compatible with Hugging Face Spaces and provides features such as deploying Hugging Face Spaces, utilizing environment variables, and more.
Lilac is particularly well-suited for businesses with specific data requirements and can be seamlessly integrated with various data stacks. To assist users, Lilac offers comprehensive documentation, a web demo, and a contact for support.
Lilac image gallery
Lilac core features
❤ Data organization
❤ Exploring datasets
❤ Annotating text
❤ Conducting semantic keyword searches
❤ Labeling data in large quantities
Lilac use cases
#️⃣ Curating and improving datasets for the purpose of machine learning models.
#️⃣ Annotating and organizing data for tasks related to natural language processing.
#️⃣ Conducting semantic searches and grouping data in large datasets.