In the context of artificial intelligence, an action-value function is a key concept in reinforcement learning, a type of machine learning where an agent learns to make decisions by interacting with an environment and receiving feedback in the form of rewards or penalties. The action-value function is a mathematical representation that maps a state-action pair to the expected cumulative reward that the agent can achieve by taking that action in that state.
To understand the concept of an action-value function, it is important to first understand the basic components of reinforcement learning. In reinforcement learning, an agent interacts with an environment by taking actions and receiving feedback in the form of rewards or penalties. The goal of the agent is to learn a policy, which is a mapping from states to actions, that maximizes the cumulative reward it receives over time.
The action-value function is a fundamental concept in reinforcement learning because it provides a way for the agent to evaluate the quality of different actions in different states. By estimating the expected cumulative reward that can be achieved by taking a particular action in a particular state, the agent can make informed decisions about which actions to take in order to maximize its long-term reward.
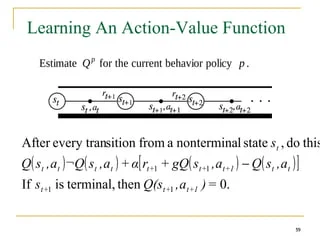
Formally, the action-value function is denoted as Q(s, a), where s is the state and a is the action. The value of Q(s, a) represents the expected cumulative reward that the agent can achieve by taking action a in state s and following its current policy thereafter. The action-value function is typically estimated using a learning algorithm, such as Q-learning or deep Q-networks, which update the estimates of Q(s, a) based on the agent’s experiences in the environment.
One of the key advantages of using an action-value function in reinforcement learning is that it allows the agent to make decisions based on the long-term consequences of its actions. By estimating the expected cumulative reward of different actions, the agent can explore the environment more effectively and learn a policy that maximizes its overall reward.
In practice, the action-value function is often represented as a table or a function approximator, such as a neural network. The agent uses this representation to estimate the value of different actions in different states and update its policy accordingly. By continuously updating its estimates of the action-value function based on its experiences in the environment, the agent can learn to make better decisions over time.
Overall, the action-value function is a fundamental concept in reinforcement learning that allows agents to evaluate the quality of different actions in different states and make informed decisions to maximize their long-term reward. By estimating the expected cumulative reward of different actions, the agent can learn an optimal policy that achieves the best possible outcome in a given environment.
1. The action-value function is essential in reinforcement learning algorithms, as it estimates the value of taking a specific action in a given state.
2. It helps in determining the optimal policy by selecting the action with the highest value in a given state.
3. The action-value function is used in Q-learning, a popular reinforcement learning algorithm, to update the Q-values based on the rewards received from taking actions.
4. It allows the agent to learn the value of different actions in different states, enabling it to make better decisions in the future.
5. The action-value function is a key component in solving Markov decision processes and other decision-making problems in AI.
1. Reinforcement learning: Action-value functions are used in reinforcement learning algorithms to estimate the value of taking a specific action in a given state.
2. Game playing: Action-value functions are used in game playing algorithms to evaluate the potential outcomes of different actions in a game.
3. Robotics: Action-value functions are used in robotics to help robots make decisions about which actions to take in different situations.
4. Autonomous vehicles: Action-value functions are used in autonomous vehicles to help them navigate and make decisions on the road.
5. Natural language processing: Action-value functions can be used in natural language processing tasks to help machines understand and generate human language.
There are no results matching your search.
ResetThere are no results matching your search.
Reset







